From Impossible to Instant: Accountable AI for a Continent
The technology that makes trust infrastructure possible for 450 million EU citizens.
January 20, 2026
We’ve been writing about the trust problem in conversational AI. Confident answers. Invisible sources. Information that sounds authoritative whether it comes from a government health agency or a conspiracy thread.
That problem is getting worse. And until recently, we didn’t know if there was a technical solution that worked at the scale where it matters.
We’ve been running internal research on this. The results aren’t published yet, but they’re promising enough that we want to share what we’re seeing.
What We’re Working On
Trust isn’t binary. It flows through networks.
Think about how you actually decide to trust information. You don’t evaluate each claim in isolation. You look at who’s saying it, who vouches for them, what institutions they’re connected to, and how those institutions have behaved over time.
This is a graph problem. Citizens, journalists, institutions, documents, claims: all nodes. The relationships between them (who published what, who verified whom, who cited which source) are edges. To answer “how much should I trust this?” you need to trace paths through that network.
Here’s a concrete example. You ask an AI assistant: “Does Vitamin D prevent flu?” It finds two sources making claims. Which one should it believe?
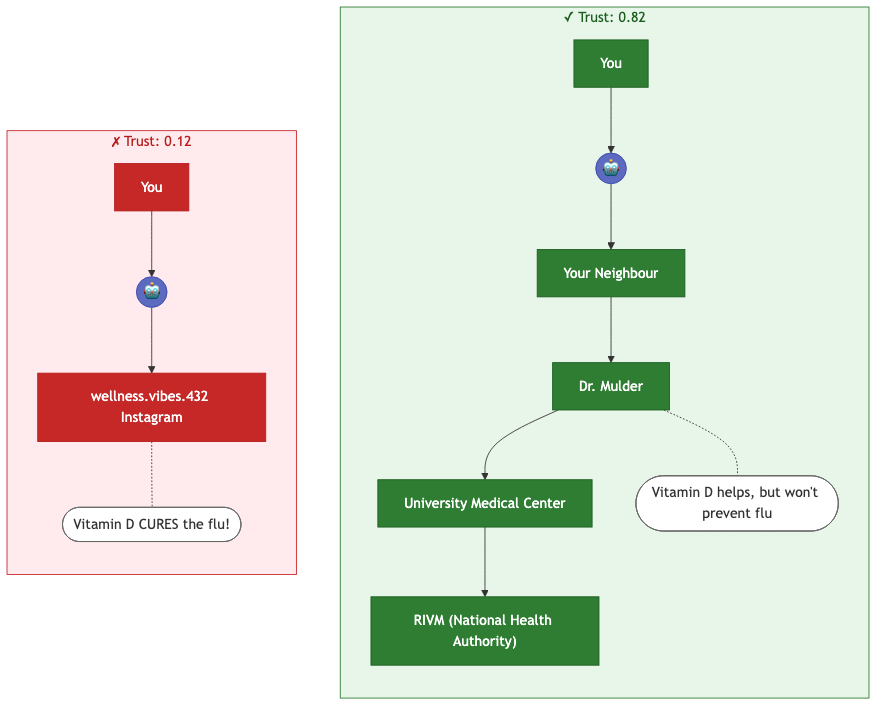
At small scale, computing this is straightforward. At the scale of a national information system, with hundreds of millions of nodes and billions of edges, generating AI answers with this kind of trust calculation has been impossible.
Until now.
The Numbers

Trust scoring has always required a trade-off: accuracy or speed. At serious scale, conventional methods break.
| Scale | Conventional Methods | Our Approach |
|---|---|---|
| 1 million nodes | 20 seconds (exact) | < 1 ms (0.85 NDCG) |
| 100 million nodes | 3–8 minutes (exact) | < 1 ms (0.85 NDCG) |
| 1 billion nodes | 50+ minutes (exact) | < 1 ms (0.85 NDCG) |
| 10 billion+ nodes | Infeasible | < 1 ms (0.85 NDCG) |
Time to trust-score 100 sources, enough to validate a single AI answer. NDCG@10Wikipedia compares our ranking to exact methods: at 0.85, the most trusted sources surface correctly, in a fraction of the time.
Look at the right column. The number doesn’t change.
Conventional methods get slower as the network grows. Ours doesn’t. Query time stays constant. It doesn’t depend on how large the graph becomes. An AI response drawing on dozens of sources, each trust-scored, returns in under a millisecond.
There’s a cost: we need to pre-compute an index. But once built, any trust query returns instantly.
The good news: trust networks are relatively stable. Institutional relationships, publication records, professional credentials: these don’t change by the minute. The index can be refreshed periodically as the network evolves, not recomputed for every query.
We’re not sacrificing accuracy to get speed. Our approach maintains ranking quality comparable to exact methods. The speedup versus exact computation: 40,000× to 87,500×.
Why This Matters
The core use case is accountable AI answers.
When you ask Hera a question, we retrieve information from many sources and synthesize a response. The question is: which sources should the AI believe? Today’s systems use popularity, recency, keyword relevance. Those signals are gamed, optimized for engagement, not trustworthiness.
With fast trust scoring, we can do something different. Before generating an answer, we can ask: “How does this source connect to institutions and people you have reason to trust?” and weight the synthesis accordingly.
Misinformation is hybrid warfare. The EU’s policy on online disinformationEuropean Commission frames it correctly: a strategic threat to democratic societies that requires defensive infrastructure.
The difference matters most when it matters most. During a health crisis, when someone asks about symptoms. During an election, when claims fly faster than fact-checkers can work. During a conflict, when state actors flood the information space with manufactured evidence.
Imagine that dynamic playing out through conversational AI. The synthesis would be seamless. The confident answer would blend verified evidence with manufactured lies, at the speed of a chat response.
If trust verification takes hours or days, it’s useless against attacks that move in seconds. Hospitals, utilities, emergency services: during a crisis, citizens need answers they can trust, immediately.
That infrastructure hasn’t existed. We’re building it now.
What’s Next
The research isn’t published yet, but the results have been proven experimentally. We’re confident enough in the approach that we’re building it at full production scale: the trust layer that will make conversational AI safe for critical information.
We’ll be sharing more as the work progresses. Sign up below to follow our research.